
White Papers










Dell HPC NFS Storage Solution High Availability Configurations with Large Capacities
9
2.1. Availability in NSS-HA
A major goal of the NSS-HA solution is to improve storage service availability in the presence of
possible failures or faults. This goal is achieved by a “failover” process implemented by Red Hat
Enterprise High Availability Cluster software stack.
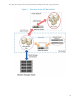
Figure 2 shows a typical scenario of how storage service availability is guaranteed in the NSS-HA
solution. In this scenario, assume a kernel crash occurs on an NFS server (the active one) which is the
NFS gateway for the compute cluster. The service availability is protected by three steps:
1) Failure detection – Resources related to the storage service, such as file system, service IP
address, etc., are defined, configured and monitored for health by the HA cluster. Any
interruption in access to the storage will be detected. In this case, once a kernel crash occurs
at NFS server 1 (the active one), a message in terms of loss of heartbeat signal will pass to NFS
server 2, and server 2 will recognize that the server 1 has failed.
2) Fencing – In the HA cluster, once a node notices that the other node has failed, it will fence
(reboot) the failed node via a fence device. This is to ensure that only one server accesses the
data at any point to protect data integrity. In NSS-HA, a node can fence the other via the Dell
iDRAC or an APC PDU. The fence devices and corresponding fence commands are configured as
part of the HA cluster configuration process. In this case, NFS server 2 will fence NFS server 1.
3) Service failover – In the HA cluster, only after a node successfully fences the other can the
service failover process be started. Failover means that the HA service running previously on
the failed server will be now transferred to the healthy one. In this case, once NFS server 2 has
successfully fenced server 1, the HA service will be transferred to and started on NFS server 2.
A failure scenario in NSS-HA Figure 2.
From the perspective of the compute cluster, there will be degradation in performance during the
actual HA failover process. But the failover is transparent to the compute cluster as far as possible and
user applications continue to function and access data as before.
The HA service can be defined and configured in the cluster configuration process. In the NSS-HA, NFS
export, the service IP via which the compute nodes access the NFS server, and LVM are configured as a
HA service.