
Administrator Guide










Performance characterization
44 Dell EMC Ready Solution for HPC PixStor Storage | Document ID
implies each thread was running on a different client), the file size was fixed at twice the amount of memory
per client, or 512 GiB.
Even that for the PixStor native client the optimum block transfer size is 8 MiB, the block size for large
sequential transfers was set to 1 MiB, since that is the maximum size used by NFS for reads and writes.
The following commands were used to execute the benchmark for writes and reads, where $Threads was the
variable with the number of threads used (1 to 512 incremented in powers of two), and threadlist was the file
that allocated each thread on a different node, using round robin to spread them homogeneously across the
16 compute nodes.
./iozone -i0 -c -e -w -r 1M -s ${Size}G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 1M -s ${Size}G -t $Threads -+n -+m ./threadlist
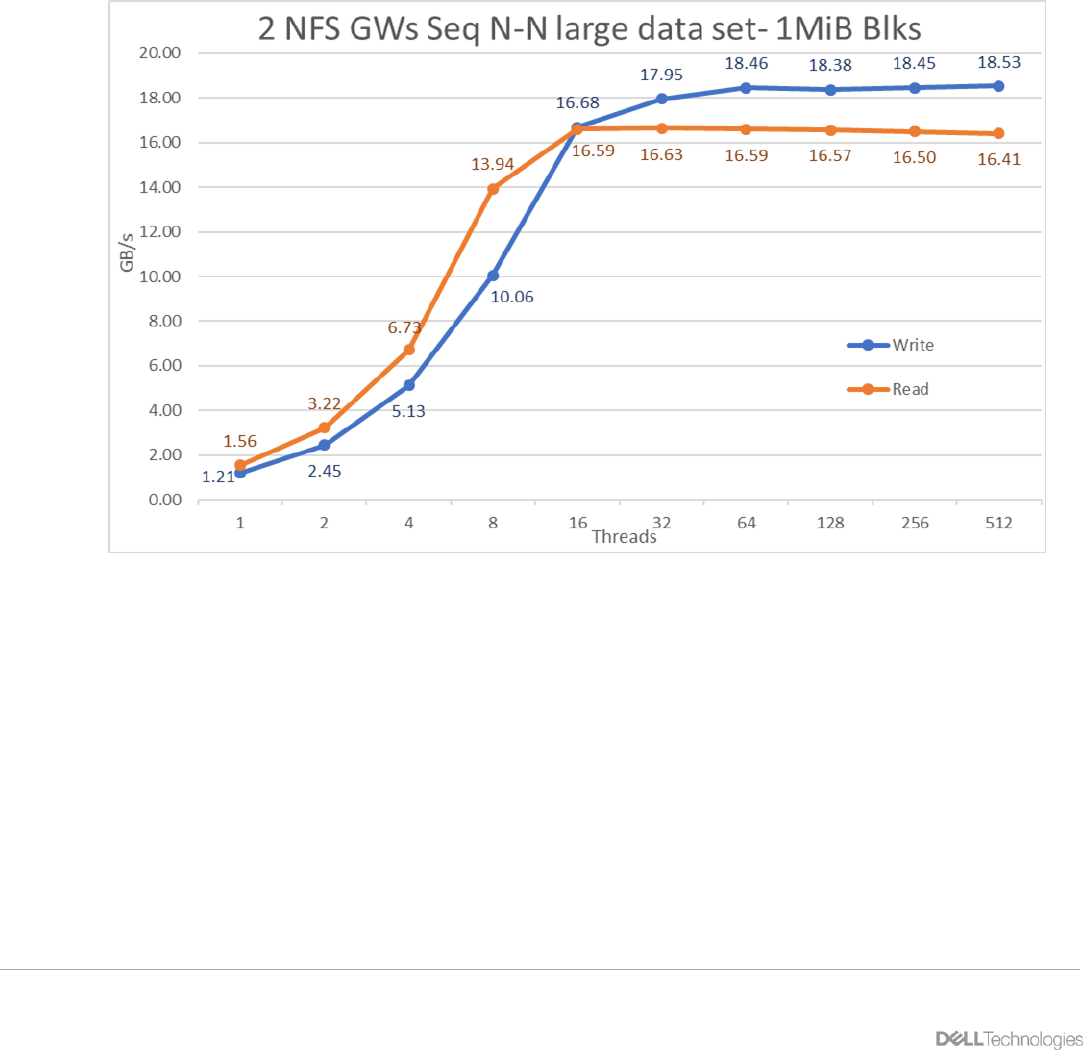
Figure 24 N to N Sequential Performance - NFS
From the results we can observe that read performance rises steadily with the number of threads, reaching
the plateau of about 16.5 GB/s with 16 threads and reaching the maximum performance of 16.63 GB/s at 32
threads.
The write performance also rises steadily until 16 threads getting to 90% pf the sustain value, and then more
slowly until reaching a plateau at 64 threads with sustained performance of about 18.3 GB/s. The maximum
read performance of 18.53 GB/s was reached at 512 threads.
SMB testing
For this testing, the same two PixStor Gateways were used exporting the PixStor file system via native OS
SMB server. Clients were mounted the FS via SMBv3 using the IP of each gateway in a round robin fashion