
Administrator Guide










Alerts
10 Prefailure alerts provided by Dell EMC PowerEdge server systems management | ID 426
2.2 System Processor (CPU) alerts
Servers have multiple CPUs, each with multiple cores, and are typically used for virtualization and high-
performance applications. As system uptime service level requirements have become increasingly stringent,
CPU manufacturing and testing processes have become correspondingly sophisticated. CPU faults are
typically unrecoverable errors. If CPU errors occur frequently, certain problems such as L2 cache error
corrections can lead to server failure. The iDRAC monitors the number of corrected errors that a CPU reports.
If the number of frequencies crosses the heuristic threshold, iDRAC writes an alert to the system log. If
configured, iDRAC sends an SNMP trap to a monitoring server. The failing CPU can then be replaced
proactively, during a scheduled maintenance window. As with SMART alerts for hard drives, a trouble ticket
can be generated, and a replacement part issued proactively.
Special actions can be put in place for servers running a hypervisor from Microsoft or VMware. If configured,
the server can go into “maintenance mode” and migrate virtual machines when a CPU alert is received.
Detailed information about how alerts work in tandem with virtual machine consoles is covered later in this
paper.
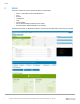
Beginning with iDRAC8, PowerEdge servers offer Compute Usage per Second (CUPS) functionality which
allows an IT administrator to monitor real-time performance the CPU, memory, and I/O. This data collection
operation is independent of operating system and does not consume CPU resources. This out-of-band, real-
time monitoring is available by RACADM, Redfish, and the iDRAC web Interface.
An example of CUPS is shown below.