
NonStop S-Series Server Description Manual (G06.27+)








Instruction Processing Environments
HP NonStop S-Series Server Description Manual—520331-004
5-6
Code and Data Allocations
Code and Data Allocations
As explained in Section 4, Memory Addressing and Access, each process has its own
separate allocation of user space in virtual memory. Within that allocation, segments
for code are assigned in the last few regions, and segments for data are assigned in
several lower address regions. The code segments contain program instructions and
constants in one or more of three possible forms (native code, Accelerator-generated
RISC code, or TNS code), and, for accelerated programs, mapping tables. The data
segments contain program variables. Each process also has a logical segment called
the process file segment (PFS), containing operating system data for the process.
The code segments of a process can be thought of as read-only storage, because no
user code instructions can write into them. Accordingly, because code segments
cannot be modified, they can be shared by any number of processes. Information in
the data segments can be both read and written, using load and store instructions—
except for those data segments that are declared to be read-only.
Every process has at least two data segments: the privileged stack segment and the
process file segment. If the process is a TNS process or if it is unprivileged, it also has
a main stack segment. A TNS process also always has a TNS user data segment (for
TNS stack and global data). A native process also has a global data segment.
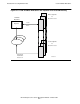
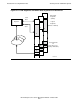
Figure 5-3 shows a simple example of three processes (A, B, and C), each executing
its own set of code segments and accumulating data in its own private data segment
(correspondingly labeled).
The process A is executing instructions fetched from code segment A, which is located
near the end of the user space in virtual memory. The process is loading data from
stack segment A, operating on that data in processor registers, and storing the
resulting data back to the data stack segment. Processes B and C, not currently in
execution, have their own code segment sets and their own data stack segments.