
Software Internationalization Guide










Software Characteristics That Vary by Locale
Software Internationalization Guide—526225-002
2-7
Multibyte Code Sets
The ISO 10646 Universal Coded Character Set
ISO 10646 is a universal coded character set (UCS) that represents all characters and
symbols from all commonly used scripts and languages. It was developed to enable
processing of groups of languages that are not usually used together. For example,
users in North Africa often need to use both French and Arabic, although these two
code sets are not commonly processed together in other parts of the world.
ISO 10646 characters are encoded in multiple octets. An octet is an eight-bit byte in
which code space is divided into four units called “group,” “plane,” “row,” and “cell.”
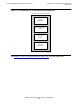
Figure 2-6 shows the character layout of ISO 10646.
ISO 10646 uses two basic forms for code elements:
•
UCS-2, in which code elements use the two lower-order octets (row and cell). This
form is also called the Basic Multilingual Plane (BMP).
•
UCS-4, in which code elements use all four octets.
Composite Characters
In addition to UCS-2 and UCS-4, ISO 10646 includes an encoding method which
enables combining multiple code elements to create composite sequences. This
method enables combining characters to allow a very wide variety of character
combinations.
The method of combining characters uses base characters, the simplest form of a
character in an alphabet, with one or more combining characters to form composite
character sequences.
For example, the letter á (lowercase a with an acute accent) exists in UCS-2 as a
single letter with the code value 0x00 0xe1. You could also encode the letter á as a
JIS X0201 Japanese
JIS X0208 Japanese
JIS X0212 Japanese
KS C 5601-1987 Korean
Figure 2-6. ISO 10646 Character Layout
Table 2-3. East Asian Code Sets (page 2 of 2)
Code Set Name Languages Supported
VST007.vsd
Group Octet Cell OctetRow OctetPlane Octet